From Monolith to Microservices
The adoption of microservice-based architectures in enterprise software systems seems to be a growing trend. The driving force behind moving from monoliths to microservices is the desire to fully leverage the benefits of cloud computing – specifically elasticity, resilience and agility.
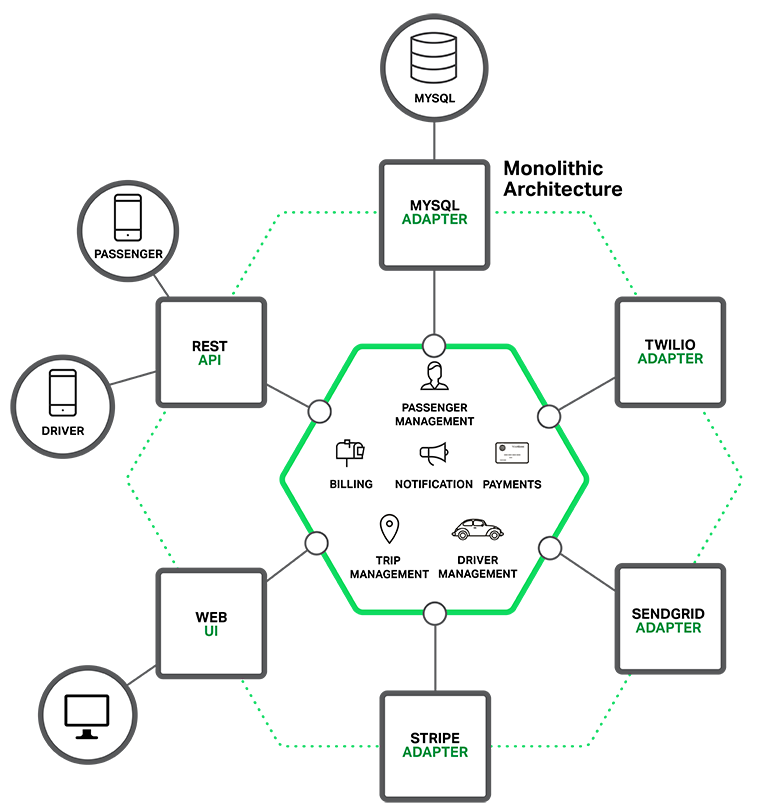
A well-designed monolith
What exactly does this transition to microservice architecture (MSA) involve?
Here’s the key takeaway:
Transitioning to microservices requires rethinking fundamental concepts and assumptions central to monolithic architectures.
Just for reference here’s a quick overview of what “Monolithic” and “Microservices” refer to:
A well-designed Monolith
A well-designed monolithic system is typically modular, with each module having clear and limited responsibilities. Interaction with external systems happens via adapters keeping the core application logic distinct from infrastructure details, like transport and persistence.
Typically this means:
- All calls between application modules are internal method calls
- Deployment is a single event involving bundling the entire application
Well-designed Microservices
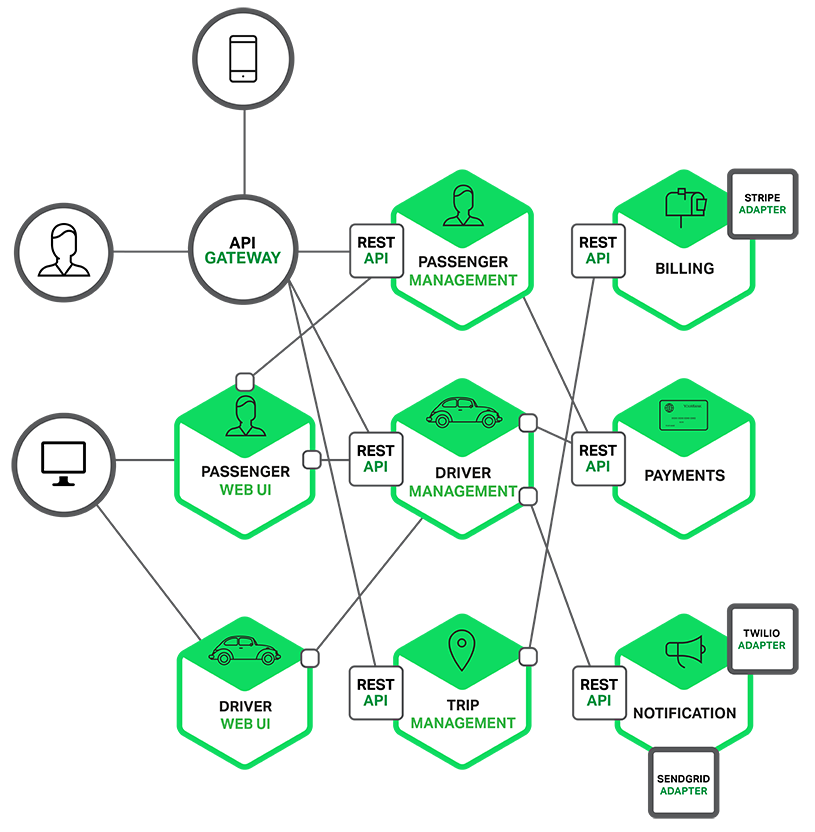
Unlike monoliths, which are typically built out of modules, microservice architectures consist of suites of independent services that are split out by business functions, with a share-nothing architecture.
Typically this means:
- Functionality is built using independent services vs internal modules
- Each service performs a well-defined business function exposed via a public API contract
- Services encapsulate functions and do not share datastores or data-models with other services
- Each service maybe changed, deployed and scaled independently
Image Credits: https://www.nginx.com/blog/introduction-to-microservices/
Given these high-level definitions, what are some fundamentals that require rethinking?
Rethink Best Practices: Distributed vs. Monolithic
Microservice architectures place such a high value on independence and resilience that best practices from monolithic applications do not always translate over.
Some examples:
-
Single Source of Truth (SSoT): Monolithic applications strive to maintain a single source of truth for each entity in it’s data model. In MSA every SSoT is a potential single point of failure (SPoF) so this is considered bad practice. It is common for key information to be cached and redundantly persisted to facilitate higher availability and resilience.
-
Don’t Repeat Yourself (DRY): The DRY principle which encourages code reuse within a monolith is often relaxed in MSA. This is because code-reuse across services is a form of coupling and service independence is given higher priority. For this reason, replicating code in various microservices is preferred over being coupled to shared libraries.
-
Unified Data Model: Monolithic applications often have a comprehensive, unified data model. Essentially this means every instance of an entity, e.g. Customer, is structurally uniform within the application. In MSA, this is considered harmful because it introduces data-coupling. Since each microservices encapsulates a business function, it should be free to model entities (perhaps with just a reference to CustomerId) within itself without affecting external services. This facilitates agility, independence and reduces data integrity errors across the system.
Rethink Communication: Message-based vs Method calls:
Monolithic applications pass data via method calls to internal modules or libraries with practically zero latency. Also, large, complex data structures maybe passed around with little to no impact on system performance.
In contrast, message-passing is the primary means of communication in MSA. A large part of processing centers around publishing, consuming, parsing, tracking, serializing and de-serializing messages. The choice of message format (JSON/XML over HTTP, RPC, ProtoBuf etc) and it’s size and complexity have systemic implications.
Rethink Deployments: Lightweight & Transient vs “Big Bang”
Monolithic applications are generally deployed infrequently and as such, significant startup and tear-down time & effort is the norm. Some manual intervention is often acceptable and factored into service-level agreements (SLAs). This is often (fondly) referred to as “big bang” deployments.
Microservices are expected to be agile and elastic. Since they must auto-scale in response variations in loads they are built as transient, lightweight components, allowing quick and automated spin-up and tear-down. As small, independent services, they can be deployed many times a day with minimal disruption.
Rethink Operations: Non-blocking vs Synchronous
In Monolithic applications, the vast majority of operations are synchronous and blocking. Events are usually internal, and used to facilitate decoupling of distinct modules. Asynchronous operations are usually delegated to Job Queues.
Since performance and availability is highly prioritized in MSA, non-blocking, asynchronous operations are preferred over blocking calls, where clients wait for the results of operations. Events often traverse the entire distributed system and are used to decouple and parallelize operations for scalability and resilience.
Rethink Consistency: Mixed vs Strong
The transactional model of relational databases (ACID) dominates how data is processed and persisted in monolithic applications. Operations are modeled to be binary in nature – either a success or a failure – and the result is immediately relayed to the user.
While the “happy path” in MSA can model atomic transactions, it’s distributed nature brings to the surface issues of strong and weak consistency. In order to offer high resiliency, performance and availability, microservices are built to tolerate varying latencies and partial failures, which often involve both strong and weak consistency models.
Rethink Concurrency: Standard vs Limited
Monolithic applications typically default to single-threaded concurrency models and when multi-threaded, concurrent processing is invoked it is carefully coordinated to prevent race-conditions and other undesirable outcomes.
The standard architecture patterns for MSA always assume concurrent processing and as such start at a much higher level of complexity in terms of process interactions. Managing and coordinating concurrent processing becomes a central architectural concern at the system level. Microservices are built with the intent of running many concurrent instances as both as consumers and producers with the system.
Rethink Observability: Systemic vs Singular
Monolithic systems typically use platform-level monitoring with embedded agents to observe system metrics from a single, central location.
The distributed nature of microservices and the focus on performance forces observability to the forefront of design. Viewing the internal state, logs and other operational details of each instance is key to understanding the system as a whole and so they expose as much information as possible in standardized, consumable formats to gather metrics, analytics and maintain audit logs of operations. This becomes even more critical when instances are transient i.e quickly spun-up to perform an operation and torn-down immediately. Distributed tracing across service boundaries is often a necessity.
Concluding thoughts:
Transitioning to microservices requires significant changes in mindset and focus. The increased elasticity, resilience and agility comes at a price – and requires solving a whole new set of problems at scale. Is it worth it? Having an in-depth understanding of the investment required is the first step to answering this question for your business.